
如何科学的遍历一颗二叉树
如何科学地遍历一颗二叉树(含莫里斯遍历,附cpp实现)
前言
二叉树很可能是你在学习数据结构与算法这门课时碰到的第一个“数据结构”,而二叉树的遍历是相当经典的算法。本文在介绍二叉树的遍历方法的同时,试图为二叉树的不同遍历方式给出一个较为一致、对称的实现。本文的二叉树定义及接口格式和Leetcode上保持一致。
以防各位工作了太久已经完全忘记课堂上讲过什么的大牛可能已经不记得什么是二叉树了,这里姑且提一句,不需要的朋友可以快进。二叉树就是形如:

这样的结构,它除唯一的头节点以外每个节点都是另一个节点的后继(入度为1)、且有不超过两个后继(出度为0~2),两个后继的位置是有区分的。一般的实现大概长这样:
struct TreeNode
{
int val; // 只是象征性的
TreeNode *left;
TreeNode *right;
};然后拿着头节点代表这一棵树。当然你也可以选择再搞一个类封一层,里面放个TreeNode*,没差。
那么为啥要遍历呢?毕竟我们把数据组织成这样是用来保存数据的,而保存了数据就要用来读取、检索、写入、删除。最基本的用例就是逐个读取其中所有的数据(由于数据存放在节点中,这等于是遍历所有的节点),因此我们需要一个方法,能够一个不落、不重复地访问每个节点一次,而且能够知道是否已经遍历结束。显然,要遍历它的难度比遍历链表不知高到哪里去了,这不是一个平凡的算法。
最小的解决方案
如果你在学习二叉树的遍历之前已经熟悉了那几种排序算法,那么“使用分治法来逐步减小问题规模”这种思路对你来说已经很熟悉了。二叉树天生就长成一副适合分治的样子(毕竟它被设计成这样就是为了方便在上面的各种算法的),这是十分自然的思路。
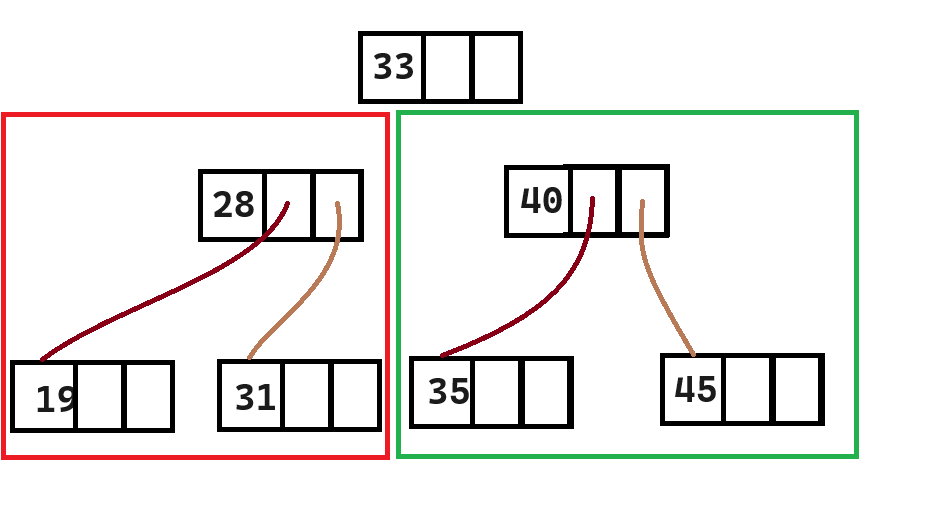
我们还是以这张图为例子:
起初,我们有根节点。我们可以立即访问到它的值33。
之后,访问以33为根的二叉树这个任务剩下的部分,就变成了访问28为根的二叉树和访问40为根的二叉树了。
 显然此处用递归是最简单的。
显然此处用递归是最简单的。
让我们试一下:
public:
vector<int> preorderTraversal(TreeNode *root)
{
vector<int> res;
preorderTraversalInternal(root, res);
return res;
}
private:
void preorderTraversalInternal(TreeNode *root, vector<int> &res)
{
if (root == nullptr)
{
return;
}
res.push_back(root->val);
preorderTraversalInternal(root->left, res);
preorderTraversalInternal(root->right, res);
}去Leetcode上跑下用例:
很好,今天的题就做到这里,下课!
…………………………
 当然没这么简单啦。
当然没这么简单啦。
遍历的次序
上一节中,我们实现了目标:
一个不落、不重复地访问每个节点一次,而且能够知道是否已经遍历结束
但你应该注意到,我们遍历的次序是:
[33,28,19,31,40,35,45]
这并不是唯一可能的次序。有些时候(如二叉搜索树之类的场景)我们会希望按照某个特定的顺序访问全部节点一次,这些特定的顺序包括:
前序遍历:∀ Node A、B,若A是B的孩子节点(下同),那么B总是在A之前被访问
中序遍历:∀ Node A、B,若A是B的左孩子,那么A总是在B之前被访问;若A是B的右孩子,那么B总是在A之前被访问;
后序遍历:∀ Node A、B,若A是B的孩子节点,那么A总是在B之前被访问
层序遍历:对于根节点来说,其层数为0;∀ Node A、B,若A是B的孩子节点,B的层数为n,则A的层数为n+1;层数低的节点总是比层数高的节点先被访问。层序遍历的实现无法和另外三种保持代码层面的一致,这里我们暂时先不去考虑。
我们之前所做的是前序遍历,这是因为我们总是访问双亲节点在访问孩子节点之前。一个便于理解的小技巧是,想象我们正在访问某一个节点,然后把他的左右子树看作是一个“大节点”。之所以能这么做是因为左子树的全部节点要么都排在当前节点前要么都排在当前节点后。对于前序遍历,当前的局面应该按照中-左-右去处理。对于中序和后序遍历,这个顺序是左-中-右和左-右-中。听上去X序遍历就是“中间”节点第X个被访问嘛。
同理,我们可以很容易写出中序遍历和后序遍历:
public:
vector<int> preorderTraversal(TreeNode *root)
{
vector<int> res;
preorderTraversalInternal(root, res);
return res;
}
private:
void preorderTraversalInternal(TreeNode *root, vector<int> &res)
{
if (root == nullptr)
{
return;
}
preorderTraversalInternal(root->left, res);
res.push_back(root->val); // 中序
preorderTraversalInternal(root->right, res);
}public:
vector<int> preorderTraversal(TreeNode *root)
{
vector<int> res;
preorderTraversalInternal(root, res);
return res;
}
private:
void preorderTraversalInternal(TreeNode *root, vector<int> &res)
{
if (root == nullptr)
{
return;
}
preorderTraversalInternal(root->left, res);
preorderTraversalInternal(root->right, res);
res.push_back(root->val); // 后序
}
非递归的遍历
上面的递归方法非常简单,只需要注意下判定递归结束就行了。那么有没有非递归的方式呢?第一次尝试实现的人都会遇到一个问题,如何返回过去曾经遍历过的节点?例如,假如现在正在做前序遍历,当前节点为31,那么该如何回到40呢?
我们知道,递归调用函数的过程中实际上是隐式地利用函数调用栈来存储信息,在递归方法中是函数调用栈帮我们记录了节点28和33的地址,以及PC所保存的当前进度信息(对于28,左右节点都已访问过;对于33,左孩子已被访问过)。如果我们也使用栈,很可能可以实现一样的效果。具体来说,我们也采取和递归过程中调用栈相似的方式,每向“下”移动一次,就把当前节点入栈;每向“上”移动一次,就把当前节点出栈。这样,栈中永远是当前节点的“上”节点。例如,访问31时,栈中永远存的是28和33。
网上给出的各种代码,写法上五花八门;三种不同循环的循环体差距极大,毫无规律可言,很多同学甚至只能硬背三种代码应付考试。至于有种“颜色法”来标记每个节点是否已访问过的算法,则额外使用了O(N)的空间,非最优解。此处尝试让三种遍历在代码上保持对称性,给出一个好记一点的方法。
所有遍历都分为三步:
找到第一个要访问的节点并入栈
出栈并访问一个节点
将后继要访问的节点入栈
不同的顺序只是对应了“如何找到第一个要访问的节点”和“如何找到后继要访问的节点”方式不同。
前序遍历:
vector<int> Solution::preorderTraversal(TreeNode *root)
{
if (root == nullptr)
return {};
stack<TreeNode *> nodes;
vector<int> ret;
TreeNode *node;
nodes.push(root); // 1.我们先找到第一个要访问的节点并入栈。对于前序遍历,这是root
do
{
// 我们假设当前出栈的节点总是剩余未访问节点中最“上左”的节点
// 2.出栈一个节点并访问之
// 此处为了让三种遍历在代码上保持对称性,使用出栈顺序作为访问顺序
node = nodes.top();
nodes.pop();
ret.push_back(node->val);
// 3.左子树需要先被访问,所以后进栈
// 如此一来,接下来就会开始访问左孩子为根的这一颗子树,且左子树中只要还有节点需要访问,
// 这些节点一直入栈,就会一直在当前这个node->right前面被出栈
if (node->right != nullptr)
nodes.push(node->right);
if (node->left != nullptr)
nodes.push(node->left);
} while (!nodes.empty());
return ret;
}中序遍历:
vector<int> Solution::inorderTraversal(TreeNode *root)
{
if (root == nullptr)
return {};
stack<TreeNode *> nodes;
vector<int> ret;
TreeNode *node = root;
// 1.找到最“左”的那个节点来开始,这是我们会访问的第一个节点。该节点满足条件“比当前节点'左'的节点已经访问完了”
do
{
nodes.push(node);
node = node->left;
} while (node != nullptr);
do
{
// 我们假设当前节点总是满足条件“比当前节点'左'的节点已经访问完了”
// 2. 出栈一个节点并访问之。
// 此处为了让三种遍历在代码上保持对称性,使用出栈顺序作为访问顺序
node = nodes.top();
nodes.pop();
ret.push_back(node->val);
// 3. 在“右”子树中找到最左的节点,留待下次访问。该节点满足条件“比当前节点'左'的节点已经访问完了”
if (node->right != nullptr)
{
node = node->right;
do
{
nodes.push(node);
node = node->left;
} while (node != nullptr);
}
} while (!nodes.empty());
return ret;
}后序遍历会遇到一点额外的困难。具体来说,当我们pop“中”的时候,我们不知道它的左右子树是否都被访问过了。
在前序遍历中,我们明确知道pop当前节点的时候它的“左”“右”都没被访问,因此可以放心入栈他们。
在中序遍历中,我们明确知道pop当前节点的时候“左”已经访问过了,“右”没有被访问。
在后序遍历的情况下,我们不得不在两种情况下抵达“中”,一种是左右都已经访问过,此时只需要pop;一种是左已经访问过了而右没有(你不可能不经过中而抵达当前的右),此时需要将右入栈。这里出现了问题。
为此,我们引入一个变量last,表示上次访问的节点。如果上次访问的节点是自己的左孩子,那就说明还需要访问右孩子;如果上次访问的是自己的右孩子,那就说明需要访问自己了。
vector<int> Solution::postorderTraversal(TreeNode *root)
{
if (root == nullptr)
return {};
stack<TreeNode *> nodes;
vector<int> ret;
TreeNode *node = root;
TreeNode *last = nullptr;
// 1.找到最“左”的那个节点来开始,这将是我们会访问的第一个节点
do
{
nodes.push(node);
node = node->left;
} while (node != nullptr);
do
{
node = nodes.top(); // 当前节点,稍后决定是否要真的出栈
if (node->right == nullptr || last == node->right)
// 比当前节点“左”的节点已经访问完了,且比当前节点“右”的节点也访问完了。出栈!
{
// 2. 出栈一个“上”节点并访问之。
node = nodes.top();
nodes.pop();
ret.push_back(node->val);
last = node; // 记录上一次访问了谁
}
else
// 比当前节点“左”的节点已经访问完了,但比当前节点“右”的节点还没有。
{
// 3. 在“右”子树中找到最左的节点,留待下次访问。该节点满足条件“比当前节点'左'的节点已经访问完了”
if (node->right != nullptr)
{
node = node->right;
do
{
nodes.push(node);
node = node->left;
} while (node != nullptr);
}
}
} while (!nodes.empty());
return ret;
}另外还有一种额外使用了O(N)空间的方法,给每个节点做个额外的记录表示是否已经访问过(而我们刚刚只使用了一个变量last来判断是否已经访问过),这种办法之所以可行,是因为递归方法中的调用栈记录了PC,也就是当前节点的代码行数执行到哪里,实际上隐含了“左右子树是否都被访问过了”这个信息。代码此处不再赘述。
层序遍历
层序遍历要求一层一层地遍历二叉树,即总是先遍历靠近根节点的那些,后遍历远离根节点的那些。我们可以使用队列来完成这个任务:首先将根节点入队。然后,每访问一个节点,将它的两个孩子节点入队。
Leetcode上的层序遍历稍微麻烦一点,还需要按层数来保存。代码中的i和j都只是用来计算当前节点所属的层数的。
vector<vector<int>> Solution::levelOrder(TreeNode *root)
{
vector<vector<int>> ret;
queue<TreeNode *> nodes;
TreeNode *rnow;
nodes.push(root);
unsigned i = 1;
unsigned j = 0;
size_t index = 0;
do
{
rnow = nodes.front();
nodes.pop();
i--;
if (rnow != nullptr)
{
if (ret.size() <= index)
{
vector<int> temp;
ret.push_back(temp);
}
ret[index].push_back(rnow->val);
nodes.push(rnow->left);
nodes.push(rnow->right);
j += 2;
}
if (i == 0)
{
i = j;
j = 0;
index++;
}
} while (!nodes.empty());
return ret;
}至此为止,你已经完全理解了如何按不同次序遍历二叉树,并且能写出递归和非递归的代码实现了。下面的内容会比较困难,而且对于实际工作来说基本上没有什么用得到的可能性并且面试也不太可能考你这个,就算你会写也不一定来得及实现正确,就算你写得出来考官也不一定看得懂 请根据自身时间精力量力而行。
很容易注意到上面的算法时间复杂度都是O(N)的(N为节点数),空间复杂度则取决于二叉树的平衡程度。较为平衡的二叉树层数应该和节点数是对数关系,需要O(logN)的空间;而最坏的情况下需要O(N)的空间(想象一条完全不分叉的二叉树)。
既然目标是遍历N个节点,时间上需要O(N)很正常。但是你看访问个单链表啥的空间复杂度都是O(1)的。有没有可能我们也用O(1)的空间复杂度来把这个事给办了呢。这……可能吗?可能吗?
答案是莫里斯遍历!
能不能再给力一点啊,老师?
线索二叉树
要知道什么是莫里斯遍历,我们不妨先来了解一下线索二叉树。
还是回到这个图:
我们注意到,在这棵树中空闲着大量的指针空间。所有叶子节点的left和right都指向了nullptr。对于非叶子节点来说也可能存在左和右其中一方为空的状况。
回忆一下我们为什么需要额外的空间才能遍历二叉树。这是因为二叉树的节点没有指向双亲节点的指针,我们只能通过显式的栈或函数调用栈来获得双亲节点的地址。与此同时,我们有这么多空着的空间,太浪费了!
线索二叉树就是按照这个思路诞生的。
“一个二叉树通过如下的方法“穿起来”:所有原本为空的右子节点指针改为指向该节点在中序序列中的后继,所有原本为空的左子节点指针改为指向该节点的中序序列的前驱。”
假设我们要对这颗二叉树进行多次中序遍历,那么我们先用常规的方式中序遍历一次,并将其变成一颗线索二叉树:
 假如我们要中序遍历线索二叉树,容易看出,只有第一个访问的节点的left和最后一个访问的节点的right是空的。我们可以从第一个访问的节点(最“左”的节点)开始,逐个找到每个节点的后继,并完成遍历。
假如我们要中序遍历线索二叉树,容易看出,只有第一个访问的节点的left和最后一个访问的节点的right是空的。我们可以从第一个访问的节点(最“左”的节点)开始,逐个找到每个节点的后继,并完成遍历。
在没有使用任何额外空间的情况下,二叉树,变成了近乎于双向链表。我们可以相当容易地以O(1)空间复杂度遍历它,代码就不再赘述了。
但这毕竟已经破坏了二叉树的结构,而且不能完全取代一般的二叉树。比如有些时候我们就是会想要知道一个节点是否是叶子结点。另外线索二叉树上要插入节点需要像链表那样操作才行。
莫里斯遍历
莫里斯遍历,就是“一边遍历二叉树一边修改二叉树,遍历的过程中通过修改二叉树上的空指针将其局部地变成线索二叉树,当一个子树被完全访问完成时又将这部分变回原来的二叉树,最后遍历完所有节点的时候二叉树也被改回原样了”这简直是魔术!
这也太复杂了,难道不是很容易把二叉树改坏了吗?但是搞清楚它的实现后,你会惊叹于这算法的巧妙的。
考虑到我们之前遇到过的难题:
非递归的情况下找不到当前节点的双亲节点,没法往上追溯 -> 引入栈来解决
后序遍历的时候不知道是第几次来到当前节点 -> 通过增加一个变量记录上一个节点来解决
而我们利用叶子节点上空间就是要一次解决这两个问题。
当我们访问某一个节点时,先找到其左子树中的最右节点,即中序遍历中该节点的前驱。
若该前驱不指向自己,则令其指向自己。这是当前节点第一次被访问的情况,此时当前节点的任何子树都是处女地。我们使树中一个尚未被访问的空白指针指向了自己,这就确保了自己会被再一次访问。
若该前驱指向自己,则令其不指向自己。 这是当前节点第二次被访问的情况,由于已经回到当前节点,我们恢复前驱指针的状态为null。
于是我们通过这简单的规则,一次性解决了向上追溯的问题和不知道第几次来到当前节点的问题。
表面上看它的时间复杂度超过了O(N),因为对于某一个节点我们进行了一个看似也是O(N)的操作,从而看似让整个算法的时间复杂度达到了O(N^2);但是仔细地分析表明,实际上每个节点至多在找前驱的过程中被用到两次。理所当然地,2N∝N。
我们上代码:
vector<int> Solution::preorder_morris(TreeNode *root)
{
vector<int> ret;
TreeNode *nodeT = root;
while (nodeT != nullptr)
{
if (nodeT->left == nullptr) // 若无左子树,立即输出,向右走
{
ret.push_back(nodeT->val); // 前序、中序
nodeT = nodeT->right;
continue;
}
else // 有左子树,需要判断是第几次来,从而知道左子树访问过了没有
{
auto prenode = nodeT->left;
while (prenode->right != nullptr && prenode->right != nodeT)
{
prenode = prenode->right; // 找到nodeT的前驱
}
if (prenode->right != nodeT)
{
ret.push_back(nodeT->val); // 前序
prenode->right = nodeT; // 若前驱不指自己,令其指自己,向左走
nodeT = nodeT->left;
}
else
{
// ret.push_back(nodeT->val); //中序
prenode->right = nullptr; // 若前驱指自己,说明是沿着它回来的
nodeT = nodeT->right; // 恢复前驱,向右走
}
}
}
return ret;
}
// 后序遍历可以用类似的思路实现,但由于各种原因没办法和前、中序的代码结构上相对应,这里偷了个懒用了reverse来让它尽可能和上面的代码像一点
vector<int> Solution::postorder_morris(TreeNode *root)
{
if(root == nullptr)
return {};
vector<int> ret;
TreeNode *nodeT = root;
while (nodeT != nullptr)
{
if (nodeT->left == nullptr) //若无左,立即输出,向右走
{
nodeT = nodeT->right;
continue;
}
else
{
auto prenode = nodeT->left;
while (prenode->right != nullptr && prenode->right != nodeT)
{
prenode = prenode->right; //找到nodeT的前驱
}
if (prenode->right != nodeT)
{
prenode->right = nodeT; //若前驱不指自己,令其指自己,向左走
nodeT = nodeT->left;
}
else
{
//这几行代码将从T到前驱路径上的节点倒序保存
auto prenode = nodeT->left;
ret.push_back(prenode->val);
int count = 1;
while (prenode->right != nullptr && prenode->right != nodeT)
{
prenode = prenode->right;
ret.push_back(prenode->val);
count++;
}
reverse(ret.end() - count, ret.end());
//这几行代码将从T到前驱路径上的节点倒序保存
prenode->right = nullptr; //若前驱指自己,说明是沿着它回来的
nodeT = nodeT->right; //恢复前驱,向右走
}
}
}
//类似的,找到根节点的双亲节点(假设有)的前驱,输出所有值
nodeT=root;
ret.push_back(nodeT->val);
int count = 1;
while (nodeT->right != nullptr && nodeT->right != root)
{
nodeT = nodeT->right;
ret.push_back(nodeT->val);
count++;
}
reverse(ret.end() - count, ret.end());
return ret;
}这一版的代码我花了很多时间去校正,但仍然没有做到三种前序、中序、后序在代码实现上的完全统一。或许,你有什么好想法?请在评论区告诉我!
莫里斯遍历的缺陷同样明显:不能遍历到过程中就中途停止,必须保证完整的进行完。否则会出现二叉树被修改了一半而状态异常。访问要加锁,不然两个线程同时读取必定能给你改的乱七八糟的。这条件很苛刻,在实际应用中还挺难保证的。但,这巧妙的算法无疑闪烁着人类智慧的光辉。许多年前,当我初次发现这个方法,我先是连夜实现了它,不这样做就无法安稳地吃饭和休息;当晚我做了一个奇异的梦,抽象的数据结构有了血肉和形体,不断肢解和重组着自身,但竟总是能安然无恙;之后的几个星期里,我常常忽然一动不动地发呆,仿佛在回味美酒的芬芳……
{kind=link}
{kind=link}